
Kluczową cechą i istotną przewagą systemu docuRob®WorkFlow nad innymi systemami zarządzania procesami biznesowymi jest jego elastyczność oraz wysoki poziom adaptacyjności. Dzięki temu możliwa jest implementacja złożonych rzeczywistych procesów, które działają w dynamicznym środowisku i często wymagają adaptowania się do zmieniającego otoczenia.
Elastyczność i adaptacyjność procesów w systemie docuRob®WorkFlow jest zapewniona poprzez połączenie siły i standardowego sposobu pracy oferowanego przez zarządzanie procesami działalności, z elastycznością i ekspresywnością mechanizmów zarządzania regułami. W takim podejściu standardowy proces jest kierowany regułami, które można definiować w wyróżnionych jego elementach. Dzięki temu osiągnięto wysoką wydajność mechanizmów regułowych zapewniając jednocześnie wysoką elastyczność procesu.
W systemie docuRob®WorkFlow mechanizm zarządzania regułami jest oparty o zapytania języka docuRob® Business Process Query Language (BPQL), którego możliwości wynikają między innymi z następujących cech języka skryptowego:
- umożliwia operowanie (definiowanie zapytań) na pełnym metamodelu procesów działalności, przedstawionym w rozdziale opisującym model informacyjny systemu. W praktyce oznacza to, że możliwe jest definiowanie zapytań, które wykorzystują informacje o definicji procesu jak i dane pochodzących z jego wykonania.
- W BPQL w prosty sposób można napisać zapytanie, które wyznaczy wykonawcę czynności bazując na wymaganiach, posiadania tego samego przełożonego co wykonawca poprzedniej czynności, posiadania określonych kompetencji, bycia zatrudnionym na odpowiednim stanowisku i posiadania najmniejszej liczby aktualnie przypisanych zadań.
- prostszy sposób działania na listach (zbiorach) danych, co w przypadku wyboru wykonawców jest najczęściej wykorzystywanym elementem.
- środowisko BPQL umożliwia dopasowanie zbioru funkcji do dziedzinowych potrzeb projektowanych procesów biznesowych. Zarówno model ontologii procesów jaki i używana terminologia i algorytmy funkcji mogą być implementowane także przez uprawnionych użytkowników platformy docuRob®WorkFlow.
Typy danych
BPQL posiada silne mechanizmy typizacji oraz weryfikacji poprawności wyrażeń pod kątem zgodności typów. Aktualnie w BPQL obsługiwane są następujące typy proste:
- String – dowolny ciąg tekstowy. Ciąg tekstowy może zawierać dowolne znaki ujęte w znaki apostrofów. Przykłady: „alabama”, „ala bama”, „Części zamienne”, „Część nr #234”,
- Integer – wartość całkowita. Przykłady: -123, 345, 0,
- Double – wartość rzeczywista. Znakiem oddzielenia części całkowitej od ułamkowej jest znak „.” Przykłady: 123.56, -23.67,
- Timestamp – data i czas. W przypadku wprowadzania stałych wartości możliwe jest podawanie tylko dat. Dopuszczalne formaty dat to: YYYY-MM-DD oraz YY-MM-DD (gdzie: Y- cyfra roku, M- cyfra miesiąca, D- cyfra dnia). Przykłady: 2001-01-01', '2008-07-23',
- Boolean -wartość logiczna. Dopuszczalne wartości to: true (prawda) oraz false (fałsz). Uwaga, ważna jest wielkość liter),
Oprócz typów prostych dostępne są też trzy typy złożone:
- Binary – reprezentuje plik nieinterpretowany przez system docuRob®WorkFlow. Może to być plik dowolnego formatu, który jest, w ramach procesu, przekazywany pomiędzy czynnościami.
- Document – kompletny dokument (plik) XML, który może być interpretowany przez reguły dostępne w BPQL.
- Node – fragment dokumentu XML (także plik) reprezentujący wierzchołek XML, który może być interpretowany przez reguły dostępne w BPQL.
W dowolnym miejscu wyrażenia BPQL można dodać komentarze. Aby rozpocząć komentarz, należy użyć symbolu „/*”. Aby zakończyć komentarz, należy użyć symbolu „*/”. Przykłady użycia są podane w kolejnych sekcjach.
Zmienne globalne procesu – atrybuty kontenera
W wyrażeniach BPQL można wykorzystywać zmienne procesu zapisane w kontenerze danych. Zmienne na poziomie procesu są wykorzystywane do przechowywania danych sterujących lub przetwarzanych przez proces.
Aby wykorzystać zmienną w wyrażeniu BPQL, należy podać jej nazwę poprzedzoną znakiem „$”.
$<nazwa_zmiennej>
W przypadku, gdy zmienna globalna jest wielowartościowa, odwołanie do jej n-tego elementu można zrealizować przy pomocy funkcji GetMultiValueAttribute
Przykłady zmiennych
$attr1
$akcept_wst
Zbiory
Jednym z kluczowych elementów BPQL są zbiory i działania na nich. W BPQL zbiorem określa się grupę nazwanych elementów o tym samym typie prostym. W zbiorze elementy mogą się powtarzać.
Większość funkcji dostępnych w BPQL zwraca rezultat w postaci zbioru. Aby utworzyć zbiór „ręcznie”, należy użyć następującej składni:
[<element1>, <element 2>, ... , <element n>]
Przykłady zbiorów
['aa', 'bb', 'cc']
[true, false]
Operatory
Operatory są kolejnym podstawowym elementem języka BPQL. Poniżej sklasyfikowano i opisano poszczególne grupy operatorów.
Logiczne
Dostępne są trzy operatory logiczne:
- NOT lub znak '~' – negacja logiczna, negowane wyrażenie musi być w nawiasach,
- AND – iloczyn logiczny,
- OR – suma logiczna.
Przykłady użycia
($x=5) AND ($y='zatwierdzono')
jest prawdziwe, gdy zmienna globalna x ma wartość 5 a zmienna globalna y ma wartość 'zatwierdzono'
IF (~($test3)) THEN
['user1'];
jeżeli zmienna test3 ma wartość fałsz (false), to wyrażenie zwróci jednoelementowy zbiór z użytkownikiem user1.
Arytmetyczne
W BPQL zdefiniowano podstawowe operatory arytmetyczne. Operatory te działają na danych typu Integer oraz Double. Są to następujące operatory:
- '+' operator sumy
- '-' operator różnicy
- '*' operator mnożenia
- '/' operator dzielenia
Przykład użycia
IF ($x = 2* $y + 3) THEN
['user1'];
jest prawdziwe, gdy zmienna globalna x ma wartość o trzy większą niż wartość dwa razy większa od wartości zmiennej y.
Operatory porównania
W języku BPQL zdefiniowano wszystkie standardowe operatory porównania:
- '=' równy
- '>' większy
- '>=' większy lub równy
- '<' mniejszy
- '<=' mniejszy lub równy
- '<>' różny
Operatory porównania są dostępne dla następujących typów prostych: Integer, Double, Timestamp oraz String. W przypadku tekstów operatory mniejszości i większości działają w sposób standardowy jak dla języków programowania.
Przykład użycia
IF (($x = false) AND ($data < 2008-01-01)) THEN
['user1'];
ELSE IF (($x = true) AND ($wartosc <= 1000)) THEN
['user2'];
ELSE
['user3'];
Jeżeli wartość x jest fałszem i data wniosku jest wcześniejsza niż w roku 2008 to zwróć jako rezultat wykonawcę user1. W przeciwnym wypadku sprawdź czy wartość x jest prawdą i czy wartość delegacji jest większą niż 1000 PLN. Jeżeli tak to zwróć wykonawcę user2. W przeciwnym wypadku zwróć wykonawcę user3.
Działania na zbiorach
Kolejnym zestawem operatorów są operatory działania na zbiorach. W języku BPQL dostępne są trzy podstawowe operatory:
- '/\' iloczyn zbiorów.
- '\/' suma zbiorów
- \ różnica zbiorów
Przykład użycia
UsersFromList(DepartmentUsers('100419542')) /\ WM_Fun_hasPosition('Specjalista')) \ ['user12']
Wybierz wszystkie sekretarki pracujące w komórce organizacyjnej o id '100419542' inne niż user12.
Kolejność wykonywania operatorów i nawiasy
W języku BPQL kolejność wykonywania operatorów jest taka sama jak w standardowym języku programowania. Kolejność ta została przedstawiona w Tabela 1. Aby zmienić tę kolejność, należny użyć nawiasów „( )”.
| Operatory (od najwyższego priorytetu) |
|---|
| Operatory iloczynu i ilorazu algebraicznego |
| Operatory sumy i różnicy algebraicznej |
| Operator podstawienia |
| Operator iloczynu zbiorów |
| Operator sumy i różnicy zbiorów |
| Operatory porównania |
| Operator logiczny negacji |
| Operator logiczny iloczynu |
| Operator logiczny sumy |
Tabela 1. Priorytety wykonywania operatorów w języku BPQL
W przypadku występowania kilku operatorów o tym samym priorytecie są one grupowane począwszy od lewej strony. Przykład sprawdzenia jak działa kolejność operatorów. Wyrażenie:
$x := 4 + $y * $w – 45 / $k
jest równoważne w BPQL następującemu wyrażeniu:
($x := (4 + (($y * $w) – (45 / $k))))
Instrukcje
Kolejnym ważnym elementem BPQL są instrukcje. Podstawową instrukcją jest instrukcja podstawienia, czyli przypisania wartości zmiennej. W celu zgrupowania kilku instrukcji można wykorzystać tzw. bloki instrukcji. Instrukcje umożliwiają też definiowanie rozpływu sterowania (instrukcje warunkowe) oraz masowego przetwarzania (instrukcje pętli). Dodatkowo, możliwe jest zdefiniowanie zmiennych dotyczących danego bloku instrukcji.
Instrukcja podstawienia
W BPQL operator podstawienia jest reprezentowany za pomocą symbolu „:=”. Operator ten wykonuje przypisania zmiennych o dowolnym typie prostym oraz typach złożonych: Document oraz Node. Dzięki temu operatorowi możliwe jest na przykład definiowanie miar procesu takich jak liczba obiegów danej ścieżki (cyklu).
Składnia instrukcji podstawienia jest następująca:
$<nazwa zmiennej> := <wyrażenie podstawienia>;
Przykład użycia
$liczba_obiegow := $liczba_obiegow + 1;
Podstawienie to umieszczone w preakcji danej czynności zwiększa o 1 licznik liczby wykonanych modyfikacji pisma przed jego zatwierdzeniem (liczbę obiegów pętli dotyczących modyfikacji).
Uwaga: każda instrukcja podstawienia musi być zakończona symbolem średnika!
Bloki instrukcji
Bloki instrukcji w połączeniu z instrukcjami warunkowymi pozwalają na elastyczne definiowanie bardziej złożonych reguł biznesowych procesu. Jest to szczególnie przydatne w przypadku reguł dotyczących pre i postakcji czynności.
Składnia bloku instrukcji jest następująca:
{
<instrukcja 1>
<instrukcja 2>
...
<instrukcja N>
}
Przykład użycia
Rozszerzmy ostatni przykład o zwiększenie ryzyka (prawdopodobieństwo) braku opracowania decyzji o 10% (zakładamy, że aktualne ryzyko jest < niż 90%).
{
$liczba_obiegow := $liczba_obiegow + 1;
pr_braku_decyzji := $ pr_braku_decyzji + 0.1;
}
Instrukcje blokowe można zagnieżdżać. Każda z instrukcji wewnątrz bloku instrukcji może też by blokiem instrukcji.
Zmienne lokalne
Zmienne lokalne umożliwiają definiowanie zmiennych na poziomie poszczególnych reguł (przypisania wykonawcy, warunku przejścia, pre i post akcji) oraz bloków instrukcji.
Deklaracja zmiennej ma następującą składnię:
<typ_prosty> <nazwa zmiennej>;
Jeżeli chodzi o <typ prosty> to dopuszczalne są typy proste zdefiniowane w BPQL. Jeżeli nazwa zmiennej koliduje z nazwą już istniejąca, to nie zostanie to wykryte w czasie definicji procesu a jedynie zostanie zgłoszone w formie błędu podczas jego wykonania.
Przykład użycia
Integer x;
{
$x:= 5;
Integer y;
{
$y:= $x;
Integer z;
{
$z:= $y;
}
}
}
Instrukcja warunkowa
Aby umożliwić wprowadzanie warunków w wyrażeniach języka BPQL, wprowadzono instrukcje warunkowe. Składnia tej instrukcji dopuszcza dwie możliwości:
IF ( <warunek logiczny>) THEN
<instrukcja gdy prawda>
IF ( <warunek logiczny>) THEN
<instrukcja gdy prawda>
ELSE
<instrukcja gdy fałsz>
Znaczenie tej instrukcji jest następujące: jeżeli <warunek logiczny> ma wartość prawda (true) to wykonywana jest <instrukcja gdy prawda>. W przeciwnym wypadku, jeżeli zdefiniowano klauzulę ELSE, zostanie wykonana <instrukcja gdy fałsz>. Instrukcją może być zarówno instrukcja prosta, jak i instrukcja blokowa, czy kolejna instrukcja warunkowa.
Uwaga: należy pamiętać, że wyrażenie warunkowe musi być ujęte w nawiasach!
Przykład użycia
W naszym poprzednim przykładzie sprawdzimy, czy po uaktualnieniu wartości ryzyka przekracza ono odpowiednie progi. Jeżeli ryzyko jest większe niż 50% to ustawimy zmienną Wymagana_notyfikacja_wlasciciela (procesu). Jeżeli wartość przekroczy 80% to dodatkowo ustawimy zmienną wymagana_notyfikacja_przelożonego.
{
$liczba_obiegow := $liczba_obiegow + 1;
IF ($pr_braku_decyzji < 0.9) THEN {
$pr_braku_decyzji:= $pr_braku_decyzji + 0.1;
IF ($pr_braku_decyzji > 0.5) THEN
$wymagana_notyfikacja_wlasciciela := true;
IF ($pr_braku_decyzji > 0.8) THEN
$wymagana_notyfikacja_przelozonego:= true;
} ELSE
$pr_braku_decyzji:= 1.0;
}
Pętla For
Pętla for jest podstawową instrukcją do obsługi operacji powtarzalnych wykonywanych na indeksowanej grupie danych. Składnia tej instrukcji jest następująca:
FOR ( <warunek>; <inkrementacja>)
<instrukcja>
Znaczenie tej instrukcji jest następujące: wykonuj akcję <instrukcja> (także instrukcję blokową) dopóki <warunek> jest spełniony (prawdziwy). Po każdym wykonaniu akcji, wykonaj instrukcję <inkrementacja>.
Aby wykorzystać pętlę, należy jeszcze uzupełnić ją o:
- deklaracje zmiennej licznikowej, wykorzystywanej w warunku pętli. Zmienna ta może być lokalna lub globalna.
- przypisać wartość początkową zmiennej
Dodatkowo, należy pamiętać, że instrukcja <inkrementacja> służy do odpowiedniej modyfikacji zmiennej licznikowej w pętli. Instrukcja ta może nie wystąpić w deklaracji instrukcji FOR, wtedy należy dodać jedynie znak ';' na końcu warunku.
Przykład użycia
Zakładamy, że mamy zmienną wielowartościową określająca decyzje podjęte przez poszczególnych oceniających dany wniosek. Liczba oceniających zależy od danego wniosku (instancji procesu) i jest zapisana w zmiennej globalnej $liczba_oceniajacych. Oceny są zapisane w zmiennej globalnej $oceny o typie całkowitym (dopuszczalne wartości od 1 do 5). Każda z pojedynczych ocen zapisana jest pod kluczem będącym liczbą naturalną z zakresu od 1 do $ liczba_oceniajacych. W naszym przykładzie wyznaczymy ocenę końcową będącą średnią wszystkich ocen jednostkowych i zapiszemy ją w zmiennej globalnej $ocena_koncowa.
/*
Aby przykład zadziałał, należy zdefiniować
następujące zmienne globalne:
liczba_oceniajacych Integer
ocena Integer wielowartosciowy
ocena_koncowa Double
*/
Integer i; /* zmienna licznikowa */
Integer suma; /* zliczanie sumy z ocen cząstkowych */
/* ustalenie wartości początkowych */
$i:=1;
$suma:= 0;
FOR ($i:=0; $i < $liczba_oceniajacych; $i:=$i+1) {
/* dodaj do sumy wartości jednostkowe */
$suma := $suma +
String2Int(GetMultiValueAttribute('ocena', Int2String($i)));
}
/* wyznacz ocenę końcową jako średnią ocen jednostkowych */
$ocena_koncowa := $suma / $liczba_oceniajacych
W linii 16 wykorzystujemy trzy wbudowane funkcje BPQL:
- GetMultiValueAttribute - do odczytania wartości oceny jednostkowej zapisanej pod kluczem $i. Odczytana wartość jest w postaci tekstowej (a nie liczbowej).
- Int2String – do konwersji zmiennej licznikowej na tekstową reprezentację klucza w atrybucie wielowartościowym $ocena. Klucz w atrybucie wielowartościowym jest zawsze tekstem.
- String2Int – do konwersji odczytanej wartości atrybutu wielowartościowego z postaci tekstowej na liczbową.
Pętla while
Inna odmiana pętli jest pętla WHILE. Składnia tej instrukcji jest następująca:
WHILE ( <warunek>)
<instrukcja>
Znaczenie tej instrukcji jest następujące: wykonuj akcję <instrukcja> (także instrukcję blokową) dopóki <warunek> jest spełniony (prawdziwy). W odróżnieniu od instrukcji FOR, w tej instrukcji <inkrement> może być zawarty w dowolnej części akcji <instrukcja>.
Przykład użycia
Nasz przykład wyznaczania wartości średniej wyglądałby następująco:
/*
Aby przykład zadziałał, należy zdefiniować
następujące zmienne globalne:
liczba_oceniajacych Integer
ocena Integer wielowartosciowy
ocena_koncowa Double
*/
Integer i; /* zmienna licznikowa */
Integer suma; /* zliczanie sumy z ocen cząstkowych */
/* ustalenie wartości początkowych */
$i:=1;
$suma:= 0;
WHILE ($i < $liczba_oceniajacych) {
/* dodaj do sumy wartości jednostkowe */
$suma := $suma +
String2Int(GetMultiValueAttribute('ocena', Int2String($i)));
$i:=$i+1;
}
/* wyznacz ocenę końcową jako średnią ocen jednostkowych */
$ocena_koncowa := $suma / $liczba_oceniajacych
Funkcje wbudowane
Elementem pozwalającym elastycznie rozbudowywać funkcjonalność języka BPQL są funkcje. Aktualnie w BPQL istnieje zestaw ponad 100 wbudowanych funkcji. Dodatkowo każda aplikacja wykorzystująca platformę może dodawać własne specyficzne funkcje. Także w konkretnym wdrożeniu funkcjonalność języka może być elastycznie rozszerzana o nowe funkcje.
W BPQL funkcje mogą być zagnieżdżone. Jedna funkcja może być parametrem drugiej a ta z kolei może być parametrem trzeciej funkcji. Składnia użycia funkcji jest następująca
<nazwa funkcji>( <parametr1>, <parametr2>, ..., <parametrN>)
Nazwa funkcji jest ciągiem liter, liczb i znaków podkreśleń, rozpoczynającym się od litery. W nazwie funkcji nie mogą się znaleźć polskie znaki diakrytyczne.
Poniższe sekcje opisują poszczególne funkcje wbudowane w BPQL. Dla każdej z funkcji podano jej specyfikację, opis znaczenia oraz, w przypadku bardziej złożonych funkcji przykład użycia.
Funkcje te umożliwiają wykonywanie jawnych konwersji na danych różnych typów.
Funkcje działania na historii procesu oraz modyfikujące ograniczenia czasowe
BPQL dostarcza zestaw funkcji umożliwiających złożoną analizę instancji procesów oraz danych z ich wykonania. Tworzone reguły mogą zostać oparte nie tylko na wartościach bieżących atrybutów, ale również na informacji historycznej oraz ilościowej związanej np. z zakończonymi lub realizowanymi instancjami czynności. Dodatkowo istnieje możliwość dynamicznej modyfikacji ograniczeń czasowych związanych z poszczególnymi czynnościami lub z samym procesem.
ChangeActDeadline
Funkcja zmieniająca termin zakończenia wskazanej instancji czynności – przyjmuje dwa parametry : numer czynności lub identyfikator instancji czynności oraz nowy termin zakończenia instancji czynności; zwraca ustawiony nowy termin Składnia funkcji jest następująca:
Timestamp ChangeActDeadline(String actNo|actInstId, Timestamp newDeadline)
ChangeProcDeadline
Funkcja zmieniająca termin zakończenia instancji procesu – przyjmuje jeden parametr typu Timestamp, zwraca ustawiony nowy termin. Składnia funkcji jest następująca:
Timestamp ChangeProcDeadline(Timestamp newDeadline)
ChangeStoperDeadline
Funkcja umożliwiająca bardzo elastyczne oraz zmienne w czasie ustawienie oczekiwania czynności typu „Stoper” na podstawie następujących parametrów: inicjalnego czasu oczekiwania (initDeadline), iteracji, po której czas oczekiwania ma zacząć ulegać zmianie (startIdx), co ile wykonań czas oczekiwania ma ulegać zmianie (iterRange), o ile czas oczekiwania ma się zmieniać (deadlineInc), graniczny (maksymalny) czas oczekiwania (maxDeadline). Wartości wszystkich parametrów wyrażone są w milisekundach. Składnia funkcji jest następująca:
Integer ChangeStoperDeadline(String initDeadline, String startdx, String iterRange, String deadlineInc, String maxDeadline)
Funkcja ChangeStoperDeadline może być wykorzystywana jedynie w definicji czynności typu „Stoper” – przykład :
ChangeStoperDeadline(‘5000’, ‘3’, ‘2’, ‘1000’, ‘15000’);
Pierwsze, drugie oraz trzecie wykonanie czynności Stoper będzie oczekiwało 5 sek, czwarte i piąte 6 sek, szóste i siódme 7 sek itd. Czas oczekiwania będzie rósł do wartości 15 sek. Po osiągnięciu tej granicy każde następne wykonanie będzie oczekiwało 15 sek.
SetAlertTimeForNotOpenedActivities
Funkcja umożliwia ustawienie maksymalnego czasu oczekiwania na podjęcie czynności przez wykonawcę (otwarcie zadania) w ramach bieżącej instancji procesu. Jeśli w tak określonym czasie wykonawca nie podejmie zadania, wówczas system wygeneruje zdarzenie typu : ACTIVITY_INST_OPEN_TIME_EXCEED, które może być wykorzystane do np. wysłania informacji przypominającej w/w wykonawcy o oczekującym zadaniu. Parametrem funkcji jest czas oczekiwania wyrażony w minutach. Składnia funkcji jest następująca:
SetAlertTimeForNotOpenedActivities(Integer timeToWait)
Przykład:
SetAlertTimeForNotOpenedActivities(240);
Dla każdej niepodjętej czynności w bieżącej instancji procesu - po upłynięciu 4h (240 min) od jej utworzenia - zostanie wygenerowane zdarzenie o niepodjęciu zadania.
WM_Fun_FirstAct
Funkcja zwraca identyfikator pierwszej instancji czynności. Składnia funkcji jest następująca:
String WM_Fun_FirstAct()
Funkcje obsługi wykonawców
Jedną z podstawowych kategorii funkcji BPQL jest zestaw funkcji do obsługi wykonawców. Zestaw ten pozwala na wybieranie kandydatów do wykonania zadań pod kątem przynależności do struktury organizacyjnej, posiadanych kompetencji, pełnionych ról i innych zależności organizacyjnych. Dostarczane funkcje BPQL działają w kontekście pracowników a nie tylko osób. Oznacza to, że funkcje te wspierają model, w którym jedna osoba może pracować w wielu jednostkach organizacyjnych (komórkach organizacyjnych) i może być postrzegana w organizacji jako kilku pracowników. Konsekwentnie taka osoba, jako odrębni pracownicy, uczestniczy w przydzielanych i wykonywanych zadaniach.
Większość funkcji do obsługi wykonawców zwraca jako rezultat działania zbiór pracowników. Aby lepiej weryfikować wyrażenia, które przetwarzają takie zbiory zdefiniowano w BPQL specjalizację zbioru wykonawców. Jest ona zapisywana jako SET<Participant>. Typ ten jest traktowany jako odrębny w stosunku do typu SET. Oprócz tego wprowadzono też złożony typ Participant reprezentujący danego pracownika.
Poszczególne funkcje są opisane poniżej.
ActivityPerformers
Funkcja zwraca listę identyfikatorów pracowników, którzy byli wykonawcami czynności o podanym numerze (activityNo). Składnia funkcji jest następująca:
String ActivityPerformers(String activityNo)
AllCurrentPerformers
Funkcja zwraca wykonawców, którzy są przypisani do co najmniej jednego, wykonywanego aktualnie zadania w bieżącej instancji procesu. Składnia funkcji jest następująca:
SET<Participant> AllCurrentPerformers()
AnyParticipant
Funkcja zwraca wszystkich wykonawców Workflow. Składnia funkcji jest następująca:
SET<Participant> AnyParticipant()
CollectUsers
Funkcja zwraca listę identyfikatorów użytkowników powstałą przez połączenie dwóch przekazanych list z wyłączeniem powtórzeń. Identyfikatorem jest konto użytkownika. Składnia funkcji jest następująca:
String CollectUsers(String userAccountIdList, String userAccountIdList)
CurrentPerformer
Funkcja ta zwraca jako rezultat pracownika, który wykonuje aktualną czynność. W przypadku, gdy użyto tej funkcji w warunku przejścia, to jest zwracany wykonawca instancji czynności będącej początkiem danego przejścia. Jako rezultat zwracany jest jednoelementowy zbiór z obiektem Participant. Składnia funkcji jest następująca:
SET<Participant> CurrentPerformer()
DelayedActivitiesPerfomers
Funkcja zwraca zbiór wykonawców czynności opóźnionych w danej instancji procesu, które aktualnie zostały przypisane lub są w trakcie wykonywania. Jeżeli dodatkowo cała instancja procesu jest opóźniona, to zwracani są wszyscy wykonawcy aktualnie wykonywanych zadań. Identyfikator instancji procesu podawany jest jako argument funkcji. Jeżeli chcemy uzyskać informację dla aktualnie wykonywanej instancji procesu, to jako argument funkcji podajemy ThisProcessInst(). Jako rezultat zwracany jest zbiór obiektów typu Participant. Składnia funkcji jest następująca:
SET<Participant> DelayedActivitiesPerformers()
DepartmentExperts
Funkcja zwraca listę identyfikatorów pracowników posiadających określoną kompetencję w podanych komórkach organizacyjnych. Pierwszym parametrem jest identyfikator kompetencji (competenceIdentifier), drugim parametrem jest lista komórek w postaci listy identyfikatorów liczbowych komórek organizacyjnych (orgUnitIdList). Składnia funkcji jest następująca:
String DepartmentExperts(String competenceIdentifier, String orgUnitIdList)
DepartmentUsers
Funkcja zwraca listę identyfikatorów pracowników należących do podanych komórek organizacyjnych. Parametrem jest lista komórek w postaci listy identyfikatorów liczbowych komórek organizacyjnych (orgUnitIdList). Składnia funkcji jest następująca:
String DepartmentUsers(String orgUnitIdList)
ExpertsFromDep
Funkcja realizuje wybór osób o podanej kompetencji w ramach podanych komórek organizacyjnych (i ich wszystkich podkomórek). Pierwszym parametrem jest identyfikator kompetencji, drugim parametrem jest lista komórek organizacyjnych w postaci listy identyfikatorów liczbowych (ID) komórek. Ostatni parametr wskazuje czy ma być dodatkowo wykonane wyszukiwanie w ramach komórek nadrzędnych (wartość 'true') czy też nie (wartość 'false'). Jeżeli ostatni parametr funkcji ma wartość 'true' to poszukiwanie odbywa się po komórkach nadrzędnych aż do roota. Składnia funkcji jest następująca:
SET<Participant> ExpertsFromDep(String competenceIdentifier, String orgUnitIdList, String searchUp['true','false'])
ExpertsFromOU
Funkcja realizuje wybór osób o podanej kompetencji w ramach całej jednostki organizacyjnej (firmy). Pierwszym parametrem jest identyfikator kompetencji (competenceIdentifier), drugim parametrem jest identyfikator liczbowy (ID) jednostki organizacyjnej (companyId). Składnia funkcji jest następująca:
SET<Participant> ExpertsFromOU(String competenceIdentifier, String companyId)
GetDepIdFromUser
Funkcja zwraca identyfikator liczbowy komórki organizacyjnej na podstawie identyfikatora liczbowego pracownika (userAccountId). Składnia funkcji jest następująca:
String GetDepIdFromUser(String userAccountId)
GetParentDepartmentId
Funkcja zwraca identyfikator komórki nadrzędnej. Parametrem funkcji jest identyfikator liczbowy komórki organizacyjnej. Składnia funkcji jest następująca:
String GetParentDepartmentId(String orgUnitId)
GetProcessInstanceOwner
Funkcja zwraca jednoelementowy zbiór reprezentujący pracownika będącego właścicielem wykonywanego procesu, w kontekście którego funkcja została użyta. Składnia funkcji jest następująca:
SET<Participant> GetProcessInstanceOwner()
HasCompetence
Funkcja zwraca wartość logiczną: true, jeżeli którykolwiek ze wskazanych w parametrze pracowników posiada wskazaną kompetencję, false – w przeciwnym przypadku. Pierwszym parametrem jest lista identyfikatorów liczbowych pracowników (userAccountIdList). Drugim parametrem jest identyfikator kompetencji (competenceIdentifier). Składnia funkcji jest następująca:
Boolean HasCompetence(String userAccountIdList, String competenceIdentifier)
LeastLoadedPerformerCtx
Funkcja ta wybiera ze zbioru pracowników (typ SET<Participant>) podanych jako argument funkcji pracownika, który ma najmniejsze aktualne obciążenie. Obciążenie to jest liczone w liczbie aktualnie przypisanych zadań na pracownika. Jako rezultat zwracany jest obiekt typu Participant. Składnia funkcji jest następująca:
Participant LeastLoadedPerformerCtx(SET<Participant> candidates)
Participant
Funkcja umożliwia tzw. „ręczne” tworzenie obiektu reprezentującego danego pracownika w postaci obiektu Participant. Jako argumenty funkcji należy przekazać:
- login pracownika
- wartość atrybutu attr1 – atrybut ten może mieć specyficzne znaczenie w poszczególnych systemach wykorzystujących docuRob®WorkFlow. Najczęściej reprezentuje identyfikator jednostki organizacyjnej, w której pracuje dany pracownik
- wartość atrybutu attr2 – atrybut ten może mieć specyficzne znaczenie w poszczególnych systemach wykorzystujących docuRob®WorkFlow. Najczęściej reprezentuje identyfikator komórki organizacyjnej, w której pracuje dany pracownik
W przypadku, gdy nie chcemy podawać wartości attr1 i attr2, należy podać pusty ciąg znaków. Składnia funkcji jest następująca:
Participant Participant(String login, String attr1, String attr2)
ParticipantsList
Funkcja zwraca listę identyfikatorów pracowników na podstawie listy wykonawców. Składnia funkcji jest następująca:
String ParticipantsList(SET<Participant>)
SelectRandomParticipantCtx
Funkcja wybiera losowo ze zbioru podanego jako argument funkcji N pracowników i zwraca ich w postaci zbioru obiektów Participant. Składnia funkcji jest następująca:
SET<Participant> SelectRandomParticipantCtx(SET<Participant> candidates, String numberToReturn)
Subordinates
Funkcja zwraca zbiór pracowników będących bezpośrednimi podwładnymi pracowników podanych jako argument funkcji. Parametrem funkcji jest lista identyfikatorów liczbowych pracowników (userAccountIdList), dla których szukani są podwładni. Jako rezultat zwracany jest zbiór obiektów typu Participant. Składnia funkcji jest następująca:
SET<Participant> Subordinates(String userAccountIdList)
SupervisorCtx
Funkcja zwraca jako rezultat pracownika będącego bezpośrednim przełożonym pracownika podanego jako argument funkcji. Jako rezultat zwracany jest obiekt typu Participant. Składnia funkcji jest następująca:
Participant SupervisorCtx(Participant worker)
UserHasRoleInDep
Funkcja ta zwraca jako rezultat zbiór pracowników pełniących określoną rolę w komórce organizacyjnej. Identyfikator roli (roleInDepIdentifier) przekazywany jest jako pierwszy parametr funkcji. Drugim parametrem jest lista komórek organizacyjnych w postaci listy identyfikatorów liczbowych komórek (OrgUnitIdList). Jako rezultat zwracany jest zbiór obiektów typu Participant. Składnia funkcji jest następująca:
SET<Participant> UserHasRoleInDep(String roleInDepIdentifier, String OrgUnitIdList);
UserHasRoleInWorkgroup
Funkcja ta zwraca jako rezultat zbiór pracowników pełniących określoną rolę w grupie roboczej. Identyfikator roli (roleInWorkgroupIdentifier) przekazywany jest jako pierwszy parametr funkcji. Drugim parametrem jest lista grup roboczych w postaci listy identyfikatorów liczbowych (workgroupIdList). Jako rezultat zwracany jest zbiór obiektów typu Participant. Składnia funkcji jest następująca:
SET<Participant> UserHasRoleInWorkGroup(String roleInWorkgroupIdentifier, String workgroupIdList)
UserId2Login
Funkcja odczytuje login użytkownika na podstawie jego identyfikatora w systemie. Składnia funkcji jest następująca:
String UserId2Login(String userId)
UsersFromList
Funkcja zwraca wykonawców Workflow na podstawie listy identyfikatorów liczbowych pracowników (userAccountIdList). Składnia funkcji jest następująca:
SET<Participant> UsersFromList(String userAccountIdList)
Jeżeli funkcje zwracają listy identyfikatorów pracowników, to aby skorzystać z nich do określania wykonawców zadań należy wywołać je jako parametry funkcji UsersFromList(), np.
UsersFromList(DepartmentUsers('100419542'))
WM_Fun_ActivityLastPerformer
Funkcja ta wybiera pracownika, który jako ostatni wykonywał czynność lub instancję czynności podaną jako argument funkcji. Funkcja automatycznie sprawdza, czy został podany identyfikator czynności, czy identyfikator instancji czynności (zadania). Funkcja wybiera z listy wykonawców instancji czynności, które są aktualnie wykonywane lub były wykonywane w przeszłości i zakończyły się pozytywnie. Wykonawcy, którzy uczestniczyli w przerwanych czynnościach nie są brani pod uwagę. W przypadku, gdy podany został identyfikator czynności, jako ostatni wykonawca może być rozpatrywany więcej niż jeden pracownik (wiele instancji). W takim wypadku system losowo wybiera jednego z nich i zwraca jako rezultat. Rezultat ma postać jednoelementowego zbioru SET<Participant>. Składnia funkcji jest następująca:
SET<Participant> WM_Fun_ActivityLastPerformer(String activityId)
WM_Fun_ActivityOwner
Funkcja zwraca zbiór wszystkich wykonawców czynności (zbiór pracowników) lub instancji czynności (zadania) podanej jako argument funkcji. Funkcja automatycznie sprawdza, czy został podany identyfikator czynności, czy identyfikator instancji czynności (zadania). Funkcja usuwa duplikaty wykonawców (np. w przypadku pętli) ze zwracanego zbioru. Składnia funkcji jest następująca:
SET<Participant> WM_Fun_ActivityOwner(String activityId)
WM_Fun_Any
Funkcja zwraca zbiór wszystkich pracowników organizacji. Jako rezultat zwracany jest zbiór obiektów typu Participant. Ze względu na wielkość zwracanego zbioru funkcji nie należy wykorzystywać w instalacji produkcyjnej. Funkcja może jedynie służyć do celów testowych przy uruchamianiu procesu. Składnia funkcji jest następująca:
SET<Participant> WM_Fun_Any()
WM_Fun_hasPosition
Funkcja ta zwraca jako rezultat zbiór pracowników zatrudnionych na danym stanowisku, którego nazwa (lub identyfikator) przekazana jest jako argument funkcji. Jako rezultat zwracany jest zbiór obiektów typu Participant. Składnia funkcji jest następująca:
SET <Participant> WM_Fun_hasPosition(String positionName)
Przykłady użycia
Niniejsza sekcja ma na celu zaprezentowanie podstawowych przykładów użycia funkcji do obsługi wykonawców. Przykłady te są elementami reguł wyboru wykonawców.
/* Wybranie wykonawców po strukturze organizacyjnej */
UsersFromList(DepartmentUsers('100419542'))
/* Wszyscy pracownicy z komórki org. o liczbowym ID '100419542' */
/* Wybranie wykonawców po stanowiskach */
WM_Fun_hasPosition('Specjalista')
/* Wszyscy pracownicy zatrudnieni na stanowisku sekretarki*/
/* Sekretarki w komórce organizacyjnej o ID '100419542' */
UsersFromList(DepartmentUsers('100419542')) /\ WM_Fun_hasPosition('Specjalista')
/* Przełożony wykonawcy pierwszej czynności */
SupervisorCtx(WM_Fun_ActivityOwner('1'))
Funkcje konwersji danych
Funkcje konwersji danych pozwalają na wykonywanie jawnych konwersji pomiędzy typami danych wszędzie tam, gdzie: a) nie chcemy wykorzystywać niejawnych konwersji, b) nie ma niejawnych, automatycznych konwersji takich typów.
Binary2String
Funkcja konwertuje dane binarne na tekst. Parametrem są dane binarne. Jako rezultat funkcja zwraca tekst. Składnia funkcji jest następująca :
String Binary2String(Binary bin)
BinaryToBase64
Funkcja zapisuje plik binarny w kodowaniu Base64 i zwraca go w przetworzonej postaci jako tekst. Składnia funkcji jest następująca:
String BinaryToBase64( Binary file)
BinaryToHex
Funkcja zapisuje plik binarny w kodowaniu szesnastkowym (ang. hexadecimal) i zwraca go w przetworzonej postaci jako tekst. Składnia funkcji jest następująca:
String BinaryToHex( Binary file)
Boolean2String
Funkcja tworzy reprezentację tekstową wartości logicznej przekazanej jako argument funkcji. Jeżeli wartość argumentu jest prawdą, to zwracany jest tekst true. Jeżeli wartość argumentu jest fałszem, to zwracany jest tekst false. Składnia funkcji jest następująca:
String Boolean2String( Boolean value)
Date2String
Funkcja tworzy reprezentację tekstową daty przekazanej jako argument funkcji. Jeżeli data jest poprawna to zwracany jest ciąg w formacie YYYY-MM-DD HH24:MI:SS, na przykład 20080725:07:45:12. Składnia funkcji jest następująca:
String Date2String( Timestamp value)
Doc2String
Funkcja tworzy reprezentację tekstową dokumentu XML przekazanego jako argument funkcji. Składnia funkcji jest następująca:
String Doc2String( Document doc)
Double2String
Funkcja tworzy reprezentację tekstową wartości rzeczywistej przekazanej jako argument funkcji. Składnia funkcji jest następująca:
String Double2String( Double value)
Int2String
Funkcja tworzy reprezentację tekstową wartości całkowitej przekazanej jako argument funkcji. Składnia funkcji jest następująca:
String Int2String( Integer value)
Node2String
Funkcja tworzy reprezentację tekstową węzła dokumentu XML (tzw. node element) przekazanego jako argument funkcji. Składnia funkcji jest następująca:
String Doc2String( Node node)
String2Boolean
Funkcja tworzy wartość logiczną na podstawie tekstu przekazanego jako argument funkcji. Jeżeli reprezentacja argumentu funkcji jako ciąg liter pisanych (nie drukowanych) jest tekstem „true”, to funkcja zwraca wartość true. W przeciwnym wypadku funkcja zwraca wartość false. Składnia funkcji jest następująca:
Boolean String2Boolean( String value)
String2Date
Funkcja tworzy datę na podstawie tekstu przekazanego jako argument funkcji. Tekst musi być zgodny z formatem: YYYY-MM-DD HH24:MI:SS, na przykład 20080725:07:45:12. Składnia funkcji jest następująca:
Timestamp String2Date( String value)
String2Doc
Funkcja odwrotna do poprzedniej funkcji. Na podstawie reprezentacji tekstowej przekazanej jako argument funkcji parsuje ją i tworzy dokument XML.
Document String2Doc( String doc)
String2Double
Funkcja tworzy liczbę rzeczywistą na podstawie tekstu przekazanego jako argument funkcji. Separatorem części ułamkowej jest znak”.”. Składnia funkcji jest następująca:
Double String2Double( String value)
String2Int
Funkcja tworzy liczbę całkowitą na podstawie tekstu przekazanego jako argument funkcji. Składnia funkcji jest następująca:
Integer String2Int( String value)
String2Node
Funkcja odwrotna do poprzedniej funkcji. Na podstawie reprezentacji tekstowej przekazanej jako argument funkcji parsuje ją i tworzy węzeł dokumentu XML.
Node String2Doc( String doc)
Funkcje przetwarzania tekstów
Funkcje przetwarzania teksów umożliwiają wykonywanie zaawansowanych operacji na danych typu String. We wszystkich funkcjach, o ile występuje odwołanie do pozycji w tekście, pozycja ta jest podawana jako tekst, a nie jako liczba. Pozycje w tekście liczone są od wartości 1 do wartości równej długości tekstu.
CharAt
Funkcja zwraca znak (w postaci tekstu o długości 1) znajdujący się na określonej pozycji w danej tekstowej podanej jako argument funkcji. Składnia funkcji jest następująca:
String CharAt( String text, String position)
EndsWith
Funkcja sprawdza, czy dany tekst kończy się ciągiem znaków podanych jako drugi argument funkcji. Jeżeli tak jest to zwracana jest wartość prawda (true). W przeciwnym wypadku zwracana jest wartość fałsz (false).Składnia funkcji jest następująca:
Boolean StartsWith( String text, String finalText)
IndexOf
Funkcja zwraca pozycję pierwszego wystąpienia danego ciągu znaków w tekście podanym jako pierwszy argument funkcji. Składnia funkcji jest następująca:
Integer IndexOf( String text, String search)
LastIndexOf
Funkcja zwraca pozycję ostatniego wystąpienia danego ciągu znaków w tekście podanym jako pierwszy argument funkcji. Składnia funkcji jest następująca:
Integer LastIndexOf( String text, String search)
Length
Funkcja zwraca długość tekstu podanego jako argument funkcji. Składnia funkcji jest następująca:
Integer Length( String text)
LowerCase
Funkcja zwraca reprezentację tekstu podanego jako argument funkcji w którym wszystkie występujące litery są zamienione na litery pisane (małe). Składnia funkcji jest następująca:
String LowerCase( String text)
Łączenie tekstów
Do łączenia teksów wystarczy użyć operatora '+'.
Poniższy przykład podsumowuje funkcje przetwarzania tekstów i pokazuje jak można je użyć.
/* deklaracja zmiennych lokalnych */
String s;
String s1;
Boolean b;
Integer l;
$s:= 'test, test123, tesTowanie, Testujący5 ';
$s1:=CharAt($s, '1'); /* s1='t' */
$b := StartsWith($s, 'test'); /* b=true */
$b := StartsWith($s, 'testujący5'); /* b=false*/
$s := Trim($s); /* s = 'test, test123, tesTowanie, Testujący5' */
$b := StartsWith($s, 'testujący5'); /* b=false*/
$s := LowerCase($s); /* s = 'test, test123, testowanie, testujący5' */
$b := StartsWith($s, 'testujący5'); /* b=true*/
$s:= Replace($s, 'test', 'brak'); /*s='brak, brak123, brakowanie, brakujący5'*/
$s:= Set2String(Split($s, ', ', '0'), '# ');
/*
po split ['brak', 'brak123', 'brakowanie', 'brakujący5']
s='brak# brak123# brakowanie# brakujący5'
*/
$s := Set2String(Split($s, ', ', Int2String(2), '# ');
/*
po split ['brak', 'brak23, brakowanie, brakujący5']
s='brak# brak123, brakowanie, brakujący5'
*/
$s:='12345';
$l:= Length($s) /* l=5 */
$s1:= Substring($s, 2, 4); /* s= '34' */
$s:='1234512345';
$l:= IndexOf($s, '45'); /* l = 3 */
$l:= LastIndexOf($s, '45'); /* l = 8 */
Replace
Funkcja zwraca tekst, w którym zamieniono wszystkie wystąpienia ciągu znaków podanego jako drugi argument funkcji na ciąg znaków podanych jako trzeci argument funkcji. Składnia funkcji jest następująca:
String Replace( String text, String find, String replace)
Split
Funkcja dzieli tekst na fragmenty. Fragment jest tekstem, który zawiera się między separatorami. Separatorem jest ciąg znaków podanych jako drugi argument funkcji. Fragment kończy się przed kolejnym wystąpieniem separatora lub na końcu całego tekstu. Jeżeli tekst nie zawiera żadnego separatora to zwracany jest jeden fragment zawierający cały tekst. Dodatkowo, trzeci parametr określa maksymalną liczba fragmentów w wynikowym zbiorze. Jeżeli możliwy jest podział tekstu na większą niż limit liczbę fragmentów to i tak tekst zostanie podzielony jedynie na tyle fragmentów ile określono w trzecim parametrze, przy czym wykorzystany zostanie cały tekst. Wartość '0' tego parametru oznacza brak limitu. Fragmenty są zwracane w postaci zbioru. Składnia funkcji jest następująca:
SET Split( String text, String expression, String count)
StartsWith
Funkcja sprawdza, czy dany tekst rozpoczyna się ciągiem znaków podanych jako drugi argument funkcji. Jeżeli tak jest to zwracana jest wartość prawda (true). W przeciwnym wypadku zwracana jest wartość fałsz (false).Składnia funkcji jest następująca:
Boolean StartsWith( String text, String initialText)
Substring
Funkcja zwraca tekst o długości (endIndex – beginIndex) będący częścią tekstu podanego jako argument funkcji począwszy od pozycji beginIndex a skończywszy na pozycji endIndex-1. Składnia funkcji jest następująca:
Boolean Substring( String text, Integer beginIndex, Integer endIndex)
Trim
Funkcja zwraca reprezentację tekstu podanego jako argument funkcji bez spacji wiodących i kończących. Składnia funkcji jest następująca:
String Trim( String text)
UpperCase
Funkcja zwraca reprezentację tekstu podanego jako argument funkcji w którym wszystkie występujące litery są zamienione na litery drukowane. Składnia funkcji jest następująca:
String UpperCase( String text)
Funkcje przetwarzania zbiorów
W języku BPQL istnieje kilka podstawowych funkcji do operowania na zbiorach. Funkcje te pozwalają na przetwarzanie poszczególnych elementów zbioru. W składni funkcji zbiór jest podawany jako typ SET.
Bag
Funkcja ta umożliwia konwersję listy elementów na zbiór. Elementy podawane są jako kolejne argumenty funkcji bag. Elementy muszą być tego samego typu. Dopuszczalne są wszystkie typy proste oraz typ Participant. Liczba argumentów może być dowolną liczbą całkowita większą od zera. Ponieważ jest to funkcja ściśle związana z językiem, nazwa jej jest pisana małymi literami. Składnia funkcji jest następująca:
SET bag( <typ> el1, <typ> el2, ..., <typ> elN)
GetElement
Funkcja zwraca element zbioru (podany jako pierwszy argument funkcji) będący na pozycji podanej jako drugi argument funkcji. Element zwracany jest w postaci tekstu. Składnia funkcji jest następująca:
String GetElementAsString( SET set, Integer position)
GetSizeOf
Funkcja zwraca liczbę elementów w zbiorze podanym jako pierwszy argument funkcji. Składnia funkcji jest następująca:
Integer GetSizeOf( SET set)
IsEmpty
Funkcja sprawdza, czy dany zbiór jest pusty. Jeżeli tak, to zwraca wartość prawda (true). W przeciwnym wypadku zwraca wartość fałsz (false). Składnia funkcji jest następująca:
Boolean IsEmpty( SET set)
Set2String
Funkcja zapisuje wartość zbioru (wszystkich jego elementów) w postaci tekstu. Elementy zbioru są oddzielane znakiem podanym jako drugi argument funkcji. Jeżeli znak jest elementem pustym (tzn. ''), to przyjmowany jest domyślny separator. Składnia funkcji jest następująca:
String Set2String( SET set, String separator)
Dzięki tej funkcji możliwe jest zapisywanie zbiorów w zmiennych procesu celem ich dalszego przetwarzania.
String2Set
Funkcja konwertuje wartość tekstową na zbiór. Drugi argument funkcji definiuje separator wykorzystywany do oddzielenia elementów podczas parsowania tekstu. Jeżeli argument ten jest pusty (tzn. '') to wykorzystywany jest separator domyślny. Składnia funkcji jest następująca:
SET String2Set( String s, String separator)
Funkcje przetwarzania dokumentów XML
BPQL oferuje bogaty zestaw funkcji przetwarzających dokumenty XML. Funkcje te umożliwiają operowanie zarówno na całych dokumentach jak i ich elementach w postaci wierzchołków XML.
AddChildNode
Funkcja dodaje węzeł potomny do wskazanego węzła rodzica w dokumencie XML. Uaktualniony węzeł rodzica jest zwracany jako rezultat funkcji. Składnia funkcji jest następująca:
Node AddChildNode(Node parent, Node child)
AddNode
Funkcja dodaje węzeł do wskazanego dokumentu XML. Węzeł oraz dokument są przekazywane jako argumenty funkcji. Jako rezultat zwracany jest dokument XML z dołączonym węzłem. Składnia funkcji jest następująca:
Document AddNode(Document doc, Node node)
CloneDocument
Funkcja klonuje (tworzy kopię) dokumentu XML podanego jako argument funkcji. Klon jest zwracany jako rezultat funkcji. Składnia funkcji jest następująca:
Document CloneDocument(Document source)
CloneNode
Funkcja klonuje (tworzy kopię) wierzchołka dokumentu XML podanego jako argument funkcji. Klon jest zwracany jako rezultat funkcji. Składnia funkcji jest następująca:
Node CloneNode(Node source)
GetDocument
Funkcja zwraca dokument XML, w którym znajduje się węzeł dokumentu XML podany jako argument funkcji. Składnia funkcji jest następująca:
Document GetDocument(Node node)
GetNode
Funkcja zwraca wierzchołek o podanej nazwie znajdujący się w dokumencie podanym jako argument funkcji. Jeżeli jest więcej niż jeden wierzchołek o danej nazwie to zwracany jest losowo jeden z nich. Składnia funkcji jest następująca:
Node GetNode(Document doc, String name)
GetNodes
Funkcja zwraca wszystkie węzły znajdujące się w dokumencie XML podanym jako argument funkcji. Węzły zwracane są w postaci jednoelementowego zbioru. Element tego zbioru jest kolekcją węzłów o typie NodeList. Składnia funkcji jest następująca:
SET GetNodes(Document doc)
GetNodesWithName
Funkcja zwraca węzły o podanej nazwie znajdujące się w dokumencie XML. Dokument XML oraz nazwa węzła są przekazywane jako argumenty funkcji. Węzły zwracane są w postaci jednoelementowego zbioru. Element tego zbioru jest kolekcją węzłów o typie NodeList. Składnia funkcji jest następująca:
SET GetNodesWithName(Document doc, String name)
GetNodeAttributeValue
Funkcja zwraca tekstową reprezentację wartości dla danego atrybutu znajdującego się w podanym węźle. Węzeł oraz nazwa atrybutu są przekazywane jako argumenty funkcji. Składnia funkcji jest następująca:
String GetNodeAttributeValue(Node node, String attributeName)
GetValueWithXPath
Funkcja zwraca tekstową reprezentację wartości pojedynczego węzła w dokumencie XML spełniającego kryteria zapytania w języku XPath podanego jako drugi argument funkcji. Składnia funkcji jest następująca:
String GetValueWithXPath(Document doc, String xpathExpr)
GetValuesWithXPath
Funkcja zwraca wartości tekstowe węzłów w danym dokumencie, które spełniają kryteria zapytania w języku XPath podanego jako drugi argument funkcji. Wartości tekstowe zwracane są w postaci jednoelementowego zbioru. Element tego zbioru jest kolekcją o typie String. Składnia funkcji jest następująca:
SET GetValuesWithXPath(Document doc, String xpathExpr)
NewDocument
Funkcja tworzy nowy, pusty dokument XML. Składnia funkcji jest następująca:
Document NewDocument( )
NewDocumentWithRoot
Funkcja tworzy nowy dokument XML. Korzeniem utworzonego dokumentu zostaje węzeł dokumentu XML (typ Node) podany jako argument funkcji. Składnia funkcji jest następująca:
Document NewDocumentWithRoot(Node node )
NewNode
Funkcja tworzy nowy węzeł dokumentu XML (typ Node) o nazwie podanej jako argument funkcji. Składnia funkcji jest następująca:
Node NewNode(String name)
NewNodeWithNamespace
Funkcja tworzy nowy węzeł dokumentu XML (typ Node) o nazwie podanej jako argument funkcji. Węzeł tworzony jest w przestrzeni podanej jako drugi parametr funkcji. Składnia funkcji jest następująca:
Node NewNodeWithNamespace(String name, String ns)
NewTextNode
Funkcja tworzy nowy, tekstowy wierzchołek dokumentu XML (typ Node) o nazwie i wartości podanych jako argumenty funkcji. Składnia funkcji jest następująca:
Node NewTextNode(String name, String value)
NewTextNodeWithNamespace
Funkcja tworzy nowy, tekstowy węzeł dokumentu XML (typ Node) o nazwie i wartości podanych jako argumenty funkcji. Węzeł tworzony jest w przestrzeni podanej jako trzeci parametr funkcji. Składnia funkcji jest następująca:
Node NewTextNodeWithNamespace(String name, String value, String ns)
SetNodeAttribute
Funkcja zapisuje wartość atrybutu w istniejącym węźle dokumentu XML. Węzeł, nazwa atrybutu oraz wartość są podawane jako argumenty funkcji. Jeżeli dany atrybut nie istnieje, to jest zakładany. Składnia funkcji jest następująca:
Node SetNodeAttribute(Node mode, String name, String value)
Przykład
W celu zaprezentowania działania funkcji XML przygotowano następujący przykład: w danym procesie integracyjnym należy przesłać do serwera SMS listę osób (loginy), do których zostanie wysłany SMS zapraszający na spotkanie. Lista ta musi być zapisana w postaci dokumentu XML o następującej strukturze:
<zaproszenia>
<osoba>
login1
</osoba>
<osoba>
login2
</osoba>
...
</zaproszenia>
Serwer SMS na podstawie tych loginów odczyta odpowiednie numery telefonów i na podstawie tych danych (oraz innych, np. nazwy spotkania, daty i miejsca) wyśle komunikat SMS.
Przykład zapisany w języku BPQL jest następujący:
/*
Wymagane zmienne globalne
Document kandydaciXML
*/
/* zmienne lokalne */
Integer liczba;
Integer i;
String login;
Node osoba;
/*
wyznacz zbiór osób do powiadomienia
- są to dyrektorzy komórek WAD, RAD
i zapisz go w zmiennej globalnej jako tekst
*/
$kandydaci := Set2String(
(WM_Fun_OrgUnitMembers('WAD','') \/ WM_Fun_OrgUnitMembers('RAD','') /\
WM_Fun_hasPosition('DYREKTOR') ,
''
);
/* sprawdź liczbę elementów tego zbioru - wykonaj odpowiednią konwersję */
$liczba := GetSizeOf(String2Set($kandydaci), '');
/* ustawienia początkowej wartości licznika pętli*/
$i:=1;
FOR ($i<= $liczba; $i:=$i+1) {
/* odczytaj login osoby - elemen i ze zbioru*/
$login := GetElement(String2Set($kandydaci, ''), $i);
/* utwórz wierzchołek XML osoby */
$osoba := NewTextNode('osoba', $login);
/* dodaj wierzchołek do zmiennej globalnej kandydatów w XML */
$kandydaciXML := AddNode($kandydaciXML, $osoba);
}
Aby zapisać rezultat wyszukania kandydatów, wykorzystujemy zmienną globalną $kandydaciXML. Listę kandydatów (linie 16-20) otrzymujemy na podstawie iloczynu sumy zbiorów pracowników komórek organizacyjnych WAD i RAD oraz pracowników posiadających pozycję dyrektora.
Funkcje przetwarzania zbiorów w celu zapisania listy potencjalnych wykonawców w dokumencie XML reprezentowanym przez zmienna globalną $kandydaci. W przykładzie są tez wykorzystane funkcje do przetwarzania dokumentów XML.
Funkcje przetwarzania dokumentów binarnych
W języku BPQL zdefiniowano dwie funkcje do przetwarzania wielowartościowych atrybutów binarnych . Zostały one opisane w poniższych sekcjach.
GetBinaryByIndex
Funkcja ta umożliwia odczytanie pliku binarnego z atrybutu wielowartościowego używając indeksu. Nazwa atrybutu podana jest jako pierwszy argument funkcji. Indeks jest podawany jako drugi argument funkcji w postaci ciągu znaków. Składnia funkcji jest następująca:
Binary GetBinaryByIndex( String attributeName,. String index)
GetBinaryByKey
Funkcja ta umożliwia odczytanie pliku binarnego z atrybutu wielowartościowego używając klucza. Nazwa atrybutu podana jest jako pierwszy argument funkcji. Klucz jest podawany jako drugi argument funkcji w postaci ciągu znaków. W odróżnieniu od poprzedniej funkcji klucz może być dowolnym ciągiem znaków na przykład nazwa pliku. Składnia funkcji jest następująca:
Binary GetBinaryByKey( String attributeName,. String key)
Funkcje obsługi kontenera procesu
Funkcje te pozawalają na zaawansowane pobieranie oraz modyfikację atrybutów kontenera.
ClearAttributeValue
Funkcja usuwa wartość z atrybutu kontenera procesu, którego nazwa jest przekazana jako parametr. Składnia funkcji jest następująca:
ClearAttributeValue(String attrName)
ContainerAttributesToXML
Funkcja zapisuje wartości wskazanych atrybutów kontenera procesu do formatu xml. Parametry określają zbiór atrybutów podlegających zapisaniu, odpowiadające im nazwy elementów w xml oraz nazwę elementu głównego xml (root). Liczba atrybutów oraz nazw elementów musi być jednakowa. Funkcja zwraca xml w postaci typu Document. Składnia funkcji jest następująca:
Document ContainerAttributesToXML(SET attributes, SET elemNames, String xmlRootElement)
GetActAttrValue
Funkcja odczytuje atrybut lokalny instancji czynności. Nazwa atrybutu podawana jest jako argument. Składnia funkcji jest następująca:
String GetactAttrValue(String name)
GetMultiValueAttribute
Funkcja służy do odczytania z wielowartościowego atrybutu kontenera wartości wskazanej przez indeks. Odczytana wartość jest w postaci tekstowej (a nie liczbowej).
String GetMultiValueAttribute(String AttrName, String index)
GetSizeOfByName
Funkcja podaje rozmiar atrybutu wielowartościowego (liczba pozycji). Nazwa atrybutu podawana jest jako pierwszy argument funkcji. Składnia funkcji jest następująca:
Integer GetSizeOfByName( String name)
GetValueByKeyMin
Przy założeniu, że kluczami wielowartościowego atrybutu są liczby naturalne funkcja zwraca wartość, dla której klucz jest najmniejszy. Jeśli argument remove przyjmuje wartość true, zwracana wartość atrybutu wielowartościowego zostanie z niego usunięta. Składnia funkcji jest następująca:
String GetValueByKeyMin(String name, Boolean remove)
SetActAttrValue
Funkcja ustawia atrybut lokalny instancji czynności. Nazwa atrybutu podawana jest jako pierwszy argument, wartość jako drugi. Składnia funkcji jest następująca:
String SetactAttrValue(String name, String value)
Pozostałe funkcje
W niniejszej sekcji zostały opisane funkcje pomocnicze umożliwiające wykonywanie dodatkowych prac związanych z działaniem języka BPQL tj. diagnostyka, konwersje formatów czy operacje na plikach.
AddBinary2BCM
Funkcja zapisuje plik w BCM. Parametrami funkcji są kolejno: zawartość pliku, nazwa pliku, typ pliku. Jako rezultat funkcja zwraca identyfikator BCM. Składnia funkcji jest następująca :
String AddBinary2BCM (Binary file, String fileName, String mimeType)
CountSHA256
Funkcja zwraca string - skrót sha256. Parametrem jest string w formacie base64 reprezentujący zawartość pliku. Składnia funkcji jest następująca:
String CountSHA256(base64String)
CSV2XML
Funkcja umożliwiająca konwersję danych w formacie CSV na XML. Domyślnie stosowany format : <data> <row> <field> [value] </field> </row> <row>… </row>…</data> może zostać zmodyfikowany za pomocą parametrów funkcji : content – dane w formacie CSV, elementsNames – ciąg nazw oddzielonych przecinkami (alternatywne nazwy elementów <field>) – liczba musi być zgodna z ilością kolumn w danych, rowName – alternatywna nazwa elementu <row>, rootName – alternatywna nazwa elementu <data>, isHeaderRowPresent – informuje o tym, czy pierwszy wiersz zawiera nagłówki kolumn. Funkcja zwraca xml w ramach typu Document. Składnia funkcji jest następująca:
Document CSV2XML(String content, String elementsNames, String rowName, String rootName, Boolean isHeaderRowPresent)
Przykład użycia funkcji CSV2XML :
1. Document doc;
2. $content:='a, w, asas, foo, bar, ,';
3. $elementsNames := 'p1, p2, p3, p4, p5, p6, p7';
4. $rowName := 'testRow';
5. $rootName := 'testData';
6. $isHeaderRowPresent := false;
7. $doc := CSV2XML($content, $elementsNames, $rowName, $rootName, $isHeaderRowPresent);
XML2CSV
DbSelectQueryAsXML
Funkcja umożliwia wykonanie zapytania SQL typu SELECT na wskazanej w parametrach bazie danych. Wyniki zapytania zwracane są w postaci dokumentu xml o następującej strukturze : <data> <row> <field name="FIELD_NAME"> <value/> </field> … </row> … </data>, gdzie FIELD_NAME jest nazwą kolejnej kolumny ze zbioru wynikowego. Należy uważać przy formułowaniu zapytania SQL, ponieważ zbyt duży rezultat może spowodować problemy z pamięcią serwera, na którym wykonywany jest proces. Składnia funkcji jest następująca:
Document DbSelectQueryAsXML(String dbUrl, String user, String password, String query)
DbUpdateQueryExecution
Funkcja umożliwia wykonanie zapytania SQL typu UPDATE na wskazanej w parametrach bazie danych. W rezultacie zwracana jest wartość logiczna – ‘true’ jeśli zaktualizowano jakiekolwiek rekordy w bazie danych, ‘false’ w przeciwnym przypadku. Składnia funkcji jest następująca:
Boolean DbUpdateQueryExecution String dbUrl, String user, String password, String query)
Przykład użycia funkcji DbSelectQueryAsXML :
1. $url:='jdbc:oracle:thin:@my-host:1521:myDB';
2. $user:='mike';
3. $pass:='dev';
4. $query:='select first_name, last_name from PEOPLE';
5. $result := DbSelectQueryAsXML($url, $user, $pass, $query);
Debug
Funkcja zwraca jako rezultat informację o analizie i walidacji wyrażenia języka BPQL będącego argumentem funkcji. Dodatkowo funkcja zapisuje tą informację do logu systemu. Funkcja ma nieocenioną przydatność w momencie testowania nowych funkcji, które są a) złożone i trudno jest szybko prześledzić ich działanie, b) wywoływane w czynności na końcu procesu, dojście do tej czynności jest bardzo czasochłonne. Log znajduje się standardowej lokalizacji zgodnie z parametrami konfiguracji systemu. Składnia funkcji jest następująca:
String Debug(String expression)
GetIdFromIdentifier
Funkcja zwraca liczbowy identyfikator topika (pojęcia w TopicMaps) na podstawie wartości określonego atrybutu obiektu wskazanej klasy. Pierwszym parametrem jest wartość (uniqueValue), po której będzie wyszukiwany obiekt, drugim parametrem jest Publiczny Identyfikator klasy (classPublicId), trzecim parametrem jest Publiczny Identyfikator atrybutu (attributePublicId), w którym szukany obiekt posiada szukaną wartość. Składnia funkcji jest następująca:
String GetIdFromIdentifier(String uniqueValue, String classPublicId, String attributePublicId)
GetBCMFileName
Funkcja odczytuje nazwę pliku z BCM. Parametrem funkcji jest identyfikator BCM. Jako rezultat funkcja zwraca nazwę pliku. Składnia funkcji jest następująca:
String GetBCMFileName(String bcmId)
GetBCMFile
Funkcja umożliwia odczyt zawartości pliku. Parametrem funkcji jest identyfikator BCM. Jako rezultat funkcja zwraca dane binarne, które mogą być następnie przekonwertowane na inną postać np. tekst. Składnia funkcji jest następująca:
Binary GetBCMFile(String bcmId)
GetPSIById
Funkcja zwraca publiczny identyfikator topika (pojęcia w TopicMaps) na podstawie identyfikatora liczbowego tego pojęcia. Składnia funkcji jest następująca:
String GetPSIById(String topicId)
GetTMSLResult
Funkcja zwraca rezultat wykonania skryptu TMSL (Topic Map Script Language). Pierwszym parametrem jest publiczny identyfikator pojęcia (topicPSI) będącego skryptem.
Skrypt TMSL może mieć dowolną liczbę parametrów. Parametry do skryptu TMSL przekazujemy za pomocą dostępnych funkcji:
- AddParam(nazwa_parametru, wartosc_parametru, kolejny_parametr) – przekazanie do skryptu TMSL parametru o podanej nazwie i wartości
- EmptyParam() – brak kolejnego parametru
Składnia funkcji jest następująca:
GetTMSLResult(topicPSI, [ParamList])
Przykład:
// Wywołanie z pustą listą parametrów
GetTMSLResult($psiSkryptu, EmptyParam());
// Wywołanie z jednym parametrem
GetTMSLResult($psiSkryptu,
AddParam('paramName1', 'paramValue1',
EmptyParam()));
// Wywołanie z dwoma parametrami
GetTMSLResult($psiSkryptu,
AddParam('paramName1', 'paramValue1',
AddParam('paramName2', 'paramValue2',
EmptyParam()));
//…
GetValueFromJsonString
Funkcja zwraca wartość atrybutu ze stringa w formacie JSON. Parametr pierwszy to string w postaci JSON, parametr drugi to string (wg wzorca) ścieżki do parametru. Składnia funkcji jest następująca:
String GetValueFromJsonString(jsonString, pattern)
Przykłady:
GetValueFromJsonString('{"atr1":[{"atr2":"val2"}]}', 'atr1')
GetValueFromJsonString('{"atr1":[{"atr2":"val2"}]}', 'atr1/0/atr2')
ModifyDate
Funkcja modyfikuje podaną datę poprzez zmianę jej poszczególnych elementów składowych: sekund, minut, godzin, dni, miesięcy oraz roku. Do funkcji należy przekazać trzy parametry: datę, nazwę zmienianego elementu oraz dodatnią lub ujemną liczbę całkowitą, która zostanie dodana/odjęta od wskazanego elementu (np. godziny).
Poniższe przykłady prezentują dopuszczalne operacje:
Timestamp time;
$time := String2Date('2013-11-01 00:00:00');
/* dodanie 1 sekundy - zmiana czasu na 00:00:01 */
ModifyDate($time, 'SECOND', 1);
/* dodanie 1 minuty - zmiana czasu na 00:01:00 */
ModifyDate($time, 'MINUTE', 1);
/* cofnięcie o 1 godzinę - zmiana daty i czasu na 2013-10-31 23:00:00 */
ModifyDate($time, 'HOUR', -1);
/* dodanie 1 dnia - zmiana daty na 2013-11-02 */
ModifyDate($time, 'DAY_OF_MONTH', 1);
/* dodanie 1 miesiąca - zmiana daty na 2013-12-01 */
ModifyDate($time, 'MONTH', 1);
/* dodanie 1 roku - zmiana daty na 2014-11-01 */
ModifyDate($time, 'YEAR', 1);
Now
Funkcja zwraca aktualną datę systemową.
Timestamp Now()
ReadFromFile
Funkcja umożliwia odczyt zawartości pliku. Parametrami są kolejno : nazwa pliku oraz ścieżka do niego (na serwerze, na którym wykonywany jest proces). Jako rezultat funkcja zwraca dane binarne, które mogą być następnie przekonwertowane na inną postać np. tekst. Składnia funkcji jest następująca :
Binary ReadFromFile(String fileName, String pathToFile)
Przykład użycia funkcji operujących na plikach :
1. $fileName:= 'myImage.jpg';
2. $path:='/home/someUser';
3. $binary := ReadFromFile($fileName, $path);
4. $imageAsBase64 := BinaryToBase64($binary);
5. WriteToFile(‘myImgAsB64.txt’, $path, $imageAsBase64);
SHA256
Funkcja zwraca string - skrót sha256. Parametrem jest string. Składnia funkcji jest następująca:
String SHA256(inputString)
URLEncode
Funkcja zwraca string - przekonwertowany ciąg znaków, który można przesłać przez internet. Parametrem jest string. Składnia funkcji jest następująca:
String URLEncode(inputString)
WriteToFile
Funkcja umożliwia zapis tekstu do wskazanego pliku. Parametrami funkcji są kolejno: nazwa pliku, ścieżka (na serwerze, na którym wykonywany jest proces) oraz treść. Jako rezultat zwracana jest wartość logiczna, która informuje o tym, czy zapis się powiódł (‘true’ jeśli tak, ‘false’ w przeciwnym razie). Składnia funkcji jest następująca:
Boolean WriteToFile(String fileName, String pathToFile, String content)
XML2CSV
Funkcja umożliwiająca konwersję danych zapisanych w formacie XML na CSV. Parametrami funkcji są kolejno: atrybut zawierający dane w formacie xml, nazwa węzła głównego, nazwy kolejnych elementów (kolumn), które pojawią się w wynikowym formacie CSV (o ile kolejny atrybut będzie miał wartość ‘true’), atrybut wskazujący na to, czy w pierwszym wierszu wyniku mają się pojawić nazwy kolumn, znak separatora oddzielający poszczególne wartości w wynikowym CSV. Funkcja zakłada, że struktura przekazywanych danych XML będzie miała dwa poziomy zagnieżdżenia: pierwszy określający ‘wiersze’ oraz drugi, który będzie zawierał elementy z wartościami poszczególnych ‘kolumn’. Składnia funkcji jest następująca:
String XML2CSV(Document doc, String rootName, String elementsNames, Boolean isHeaderRowPresent, String separator)
Przykład użycia funkcji XML2CSV :
1. $doc:=String2Doc('<testData><r><p1>a</p1><p2>agds</p2><p3>fdfd</p3></r>
</testData>');
2. $elementsNames := 'p1,p2, p3';
3. $rootName := 'testData';
4. $isHeaderRowPresent := false;
5. $separator := ',';
6. $csvString := XML2CSV($doc, $rootName, $elementsNames, $isHeaderRowPresent,
$separator);
Inne elementy BPQL
Niniejsza sekcja opisuje pozostałe, ważne elementy pomagające poprawnie definiować i uruchamiać reguły napisane w BPQL.
Domyślne konwersje typów danych
W BPQL, w celu rozluźnienia ścisłych reguł typizacji zdefiniowano niejawne konwersje. Konwersje te zostały zaprezentowane w poniższej tabeli. Znak √ oznacza, że niejawna konwersja jest wykonywana automatycznie. Znak x oznacza, że taką konwersję należy wykonać jawnie.
| Z \ Na | String | Integer | Double | Timestamp | Boolean | Participant | Document | Node | Binary |
|---|---|---|---|---|---|---|---|---|---|
| String | x | x | x | x | x | x | x | x | |
| Integer | x | √ | x | x | x | x | x | x | |
| Double | x | x | x | x | x | x | x | x | |
| Timestamp | x | x | x | x | x | x | x | x | |
| Boolean | x | x | x | x | x | x | x | x | |
| Participant | x | x | x | x | x | x | x | x | |
| Document | x | x | x | x | x | x | x | x | |
| Node | x | x | x | x | x | x | x | x | |
| Binary | x | x | x | x | x | x | x | x |
Tabela 2. Tabela niejawnych konwersji
Weryfikacja wyrażeń BPQL
Każde z wprowadzanych wyrażeń BPQL jest weryfikowane przy zatwierdzaniu. Jeżeli jest poprawne, to narzędzie projektanta przechodzi do następnych ekranów zgodnie z aktualnym porządkiem pracy. W przypadku błędu pojawia się komunikat „Wprowadzone dane są niepoprawne”.
Po kliknięciu na przycisk Szczegóły pojawia się szczegółowa informacja o błędzie zawierająca:
- reguła, gdzie wystąpił błąd. Może to być preakcja, postakcja, warunek przejścia, dobór wykonawcy oraz definiowanie przepływu danych. Wyrażenie, które jest błędne.
- Prawdopodobna przyczyna błędu. W przypadku niezgodności typów podawane są typu, które nie pasują do siebie oraz operator lub funkcja, gdzie to niedopasowanie występuje. Identyfikator definicji procesu, której dotyczy błąd.
Weryfikacja wyrażeń BPQL następuje w momencie przejścia na inny element definicji (np. z definiowania preakcji na zakładkę specyfikacji wykonawcy) lub w momencie wywołania usługi Proces - >Weryfikuj z menu narzędzia projektowania procesów.
BPQL w działaniu
W poprzednich sekcjach przedstawiono podstawowe elementy BPQL. W tej sekcji prezentowana jest pragmatyka języka – czyli sposób użycia BPQL w poszczególnych regułach definicji procesu. Aktualnie reguły BPQL są wykorzystywane w 6 elementach definicji procesu zgodnie z tym jak pokazuje Rysunek 1.
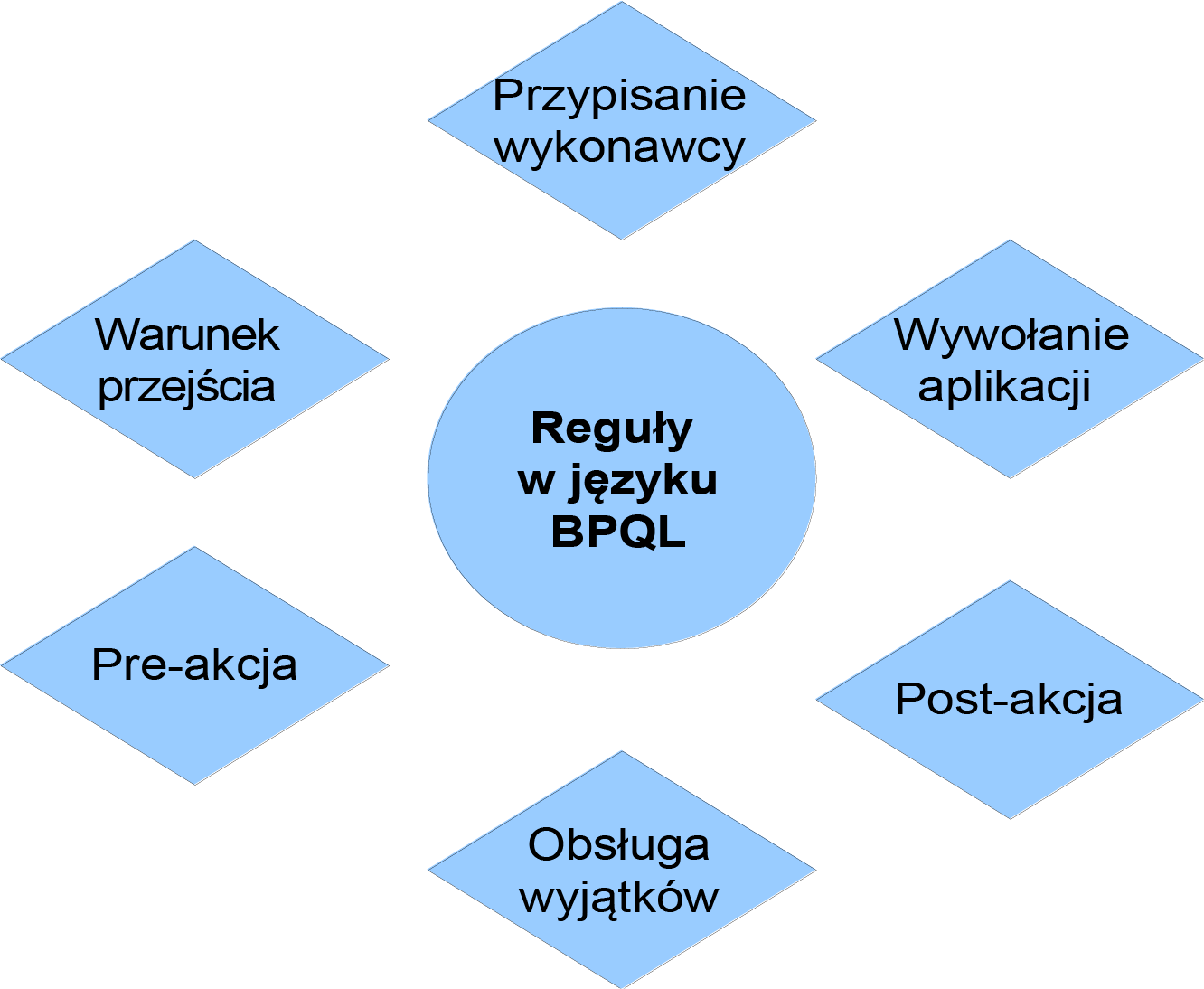
Rysunek 1: Obszary zastosowań języka BPQL
Przypisanie wykonawców
Jednym z kluczowych elementów definicji czynności jest przypisanie wykonawcy. Dana czynność może być wykonana przez jednego lub więcej wykonawców. W tym kontekście język BPQL jest używany do definicji wyboru wykonawców.
Reguły BPQL wykorzystywane do wyboru wykonawców mają jedno znaczące ograniczenie: rezultat końcowy takiej reguły musi być zbiorem pracowników (jedno lub wieloelementowym). Konsekwentnie, rezultat takiej reguły musi być reprezentowany jako typ SET<Participant>.
Wybór wykonawców w BPQL polega na konsekwentnym ograniczaniu listy kandydatów wraz z dodawaniem kolejnych wymagań na wykonawcę. Przykładowo, załóżmy, że chcemy wybrać pracownika będącego specjalistą w komórce organizacyjnej od ID '100419542' aktualnie najmniej obciążonego. Aby to zrealizować, w pierwszym kroku wybierzemy wszystkich pracowników wybranej komórki:
UsersFromList(DepartmentUsers('100419542'))
W następnym kroku rezultaty powyższego wyrażenia zawęzimy poprzez dodanie kolejnego wymagania na stanowisko wybieranych pracowników:
UsersFromList(DepartmentUsers ('100419542')) /\ WM_Fun_hasPosition('Specjalista')
W tym wypadku system docuRob®WorkFlow wyznaczy iloczyn zbiorów pracowników zwróconych przez pierwsza funkcję (pracownicy wskazanej komórki) oraz wszystkich pracowników organizacji zatrudnionych na stanowisku Specjalista. Dzięki temu jako rezultat otrzymamy pracowników, którzy jednocześnie pracują we wskazanej komórce na stanowisku Specjalista.
W ostatnim kroku zawęzimy otrzymany zbiór pracowników wybierając z niego pracownika najmniej obciążonego. Aby to wykonać, wykorzystujemy poprzednie rezultaty jako argument funkcji LeastLoadedPerformeCtx:
LeastLoadedPerformerCtx(UsersFromList(DepartmentUsers('100419542')) /\ WM_Fun_hasPosition('Specjalista'))
W rezultacie dostaniemy jednego pracownika. Na razie nasz rezultat nie może być użyty jako wyrażenie wyboru wykonawcy bo nie spełnia podstawowego założenia nie zwraca zbioru wykonawców. Aby było poprawne, musimy „opakować” rezultat funkcją bag konwertującą obiekt Participant na jednoelementowy zbiór pracowników:
bag(
LeastLoadedPerformerCtx(UsersFromList(DepartmentUsers('100419542')) /\ WM_Fun_hasPosition('Specjalista'))
)
Rezultat powyższego zapytania w BPQL jest poprawnym wyrażeniem wyboru wykonawców.
W przypadku gdy wykonawcą ma być pracownik na stanowisku Specjalista lub Starszy specjalista pracujący w komórce organizacyjnej o ID '100419542' lub '100419684', wyznaczamy zbiór potencjalnych wykonawców w następujący sposób:
UsersFromList(DepartmentUsers('100419542,100419684')) /\ (WM_Fun_hasPosition('Starszy specjalista') \/ WM_Fun_hasPosition('Specjalista') )
Przy wyborze wykonawców często wykorzystuje się instrukcje warunkowe. Przykładowo, jeżeli chcielibyśmy wybrać osobę zatwierdzającą fakturę i zróżnicować to w zależności od wysokości faktury to można byłoby to zrobić następująco:
IF ($kwota < 1000) THEN
LeastLoadedPerformerCtx(UsersFromList(DepartmentUsers('100419542')) /\ WM_Fun_hasPosition('Specjalista'));
ELSE
LeastLoadedPerformerCtx(UsersFromList(DepartmentUsers('100419542')) /\ WM_Fun_hasPosition('Starszy specjalista'));
W regule tej zachowana jest zasada zwrotu jako wartości zbioru pracowników: zarówno w przypadku spełnienia warunku jak i jego niespełnienia zostanie wybrany zbiór pracowników.
Jedną z najczęstszych pomyłek jest zakładanie, że blok instrukcji jako rezultat swojego działania może zwrócić zbiór pracowników. Niestety, aktualnie blok instrukcji nie zwraca żadnej wartości. Wobec tego nie jest możliwe użycie bloku instrukcji jako elementu, który zwraca wartość dla przypisania wykonawców. Przykładowo, poniższa reguła BPQL jest niepoprawna. System zgłasza błąd niepoprawności zwracanego rezultatu ([] versus [SET]).
IF ($kwota < 1000) THEN {
LeastLoadedPerformerCtx(UsersFromList(DepartmentUsers('100419542')) /\ WM_Fun_hasPosition('Specjalista'));
}
ELSE {
LeastLoadedPerformerCtx(UsersFromList(DepartmentUsers('100419542')) /\ WM_Fun_hasPosition('Starszy specjalista'));
}
Warunek przejścia
Kolejnym ważnym obszarem wykorzystania reguł zapisanych w BPQL są warunki przejścia. Warunki te są wykorzystywane do definiowania przepływu sterowania w procesie.
Reguły BPQL wykorzystywane do definiowania warunków przejścia mają jedno znaczące ograniczenie: rezultat końcowy takiej reguły musi być wartością logiczną. Konsekwentnie, rezultat takiej reguły musi być reprezentowany jako typ Boolean.
Przykładowo, w przypadku procesu zawierającego obsługę decyzji, jednym z warunków po akceptacji wstępnej jest sprawdzenie, czy decyzja wstępna ma wartość zaakceptowano:
$decyzja_wstepna = 'zaakceptowano'
Oczywiście wyrażenie takie można dowolnie „komplikować” zachowując zasadę, że zwracana wartość jest typu Boolean:
$decyzja_wstepna = 'zaakceptowano' AND $kwota < 1000
W warunku przejścia można też konsekwentnie użyć instrukcji warunkowej:
IF ($kwota < 1000) THEN
$decyzja_wstepna = 'zaakceptowano';
ELSE
$ decyzja_wstepna = 'zaakceptowano wstępnie';
Z drugiej strony z tych samych powodów, co dla wyboru wykonawców nie jest możliwe zastosowanie bloku instrukcji:
IF ($kwota < 1000) THEN {
$decyzja_wstepna = 'zaakceptowano';
} ELSE
$decyzja_wstepna = 'zaakceptowano wstępnie';
}
Błąd, który się pojawia dotyczy niezgodności zwracanych rezultatów.
Pre i post-akcje
Kolejnym elementem, gdzie można wykorzystać reguły BPQL są tak zwane pre i postakcje. Przy definiowaniu reguł na te akcje nie ma żadnych ograniczeń co do zwracanych wartości. Bardzo często wykorzystywane są tutaj instrukcje blokowe, pętle oraz instrukcje warunkowe. Przykład takiego wyrażenia podano poniżej:
IF ($kwota > 1000) THEN {
$priorytet := 'HIGH';
$ryzyko := $ryzyko *1.1;
} ELSE IF ($kwota < 100){
$priorytet := 'LOW';
$ryzyko := $ryzyko * 0.85;
} ELSE
$priorytet := 'NORMAL';
@beforePreAction
Jest to konstrukcja specjalnego przeznaczenia wykorzystywana w definicji pre-akcji. Przykład takiego wyrażenia podano poniżej:
@beforePreAction{
$licznik := $licznik+1;
}
/*pozostały kod pre-akcji*/
Kod zawarty w tym bloku w odróżnieniu od reszty preakcji, zostanie wykonany już podczas tworzenia czynności. W sytuacji, gdy zdefiniowanych jest n wykonawców danej czynności, blok @beforePreAction wykonany zostanie n razy podczas tworzenia czynności (tworzonych jest n instancji czynności), natomiast pozostała część preakcji wykona się raz, bezpośrednio przed wykonaniem czynności.
Parametry aplikacji i obsługi sytuacji wyjątkowych
Przy przypisywaniu parametrów aplikacji wywoływanych w czynnościach oraz zdarzeniach obsługujących sytuacje wyjątkowe możliwe jest wykorzystanie reguł BPQL. Dzięki temu można elastycznie przypisywać wartości poszczególnym parametrom wywoływanych aplikacji.
Reguły BPQL użyte do przypisań mają jedne ograniczenie: muszą zwracać wartość o typie zgodnym z typem argumentu wywoływanej aplikacji. Przykładowo, jeżeli parametr x jest tekstowy (typu String) to następujące przypisanie jest poprawne:
'x123' + $zmienna_tekstowa + Doc2String($dokument_XML)
ale wyrażenie poniżej już nie jest poprawne (zwraca wartość całkowitą a nie tekstową):
123+ $zmienna_calkowita
aby móc zapisać powyższe wyrażenie, należy dokonać jawnej konwersji typów:
Int2String(123) + $zmienna_calkowita)
Zbiór funkcji BPQL może być rozszerzany poprzez dostarczanie własnych implementacji rozszerzających klasę bazową WfWPAFunctionBase. Poniższy fragment kodu obrazuje przykładową funkcję BPQL, która zwraca do serwera wykonującego instancje procesów wylosowanych potencjalnych wykonawców czynności z dostarczonego zbioru wykonawców, w ramach której funkcja została z ewaluowana.
Dodawanie nowych implementacji funkcji BPQL
Rozbudowa możliwości platformy docuRob®WorkFlow jest dopuszczalna również dla upoważnionych użytkowników systemu. Wprowadzona do platformy możliwość rozszerzania semantyki reguł BPQL dzięki tworzeniu problemowo-zorientowanych funkcji ma znaczenie zarówno dla projektantów procesów jak i dla ich użytkowników biznesowych. W tym drugim przypadku korzyścią jest możliwość łatwej interpretacji reguł BPQL wynikającej z przyjaznej terminologii.
Implementacja przykładowej funkcji BPQL
public class SelectRandomParticipantCtx extends WfFunctionBase {
public Vector getValue(Object connection, Vector paramList) throws Exception {
// two parameters only - a set of performers and a number
ParamListHelper.checkNumberOfParameter(paramList, 2);
Vector participants = (Vector) paramList.get(0);
Vector number = (Vector) paramList.get(1);
String numberToSelect = (String) number.get(0);
int numberOfParticipantsToSelect = 0;
try {
numberOfParticipantsToSelect = Integer.parseInt(numberToSelect);
} catch (NumberFormatException e) {
throw new Exception( "Cannot convert number of participants to integer [number to convert: "+ numberToSelect+"]" );
}
return selectRandomParticipant( participants, numberOfParticipantsToSelect );
}
protected Vector selectRandomParticipant( Vector participants, int numberToSelect ) {
Vector selectedSet = new Vector( numberToSelect );
Random random = new Random();
for( int i=0; i<numberToSelect; i++ ) {
WfWPAParticipant selectedParticipant = (WfWPAParticipant) participants.get( random.nextInt( participants.size() ) );
selectedSet.add( selectedParticipant );
}
return selectedSet;
}
}
Aby funkcja BPQL była widoczna, musi zostać opisana w tabeli bazy danych TB_ZF. Opis funkcji składa się z następujących atrybutów :
- ZF_ID – kolejny w ramach tabeli identyfikator funkcji
- ZF_NAZWA – nazwa funkcji (nazwa klasy implementującej funkcję)
- ZF_LICZBA_PARAM – liczba parametrów funkcji
- ZF_PARAMETRY – typy danych parametrów funkcji (oddzielone przecinkiem)
- ZF_OPIS – opis funkcji
- ZF_RESULT – typ danych rezultatu funkcji
- ZF_CLASS – pełna nazwa klasy (wraz z pakietem) implementującej funkcję
Dla powyższej funkcji opis wygląda następująco :
INSERT INTO TB_ZF (ZF_ID, ZF_NAZWA, ZF_LICZBA_PARAM, ZF_PARAMETRY, ZF_OPIS, ZF_RESULT, ZF_CLASS) VALUES ('35', 'SelectRandomParticipant', 2, 'SET,String', 'Losowy wybór wykonawcy ze zbioru', 'SET', 'pl.rodan.ooworkflow.environment.resource.wpa.SelectRandomParticipant');